一个打杂架构师的爬虫日常
文章目录
最近又双叒叕开始写起了爬虫。
写一个爬虫的思路
链接发现
- 有序/规则 -> 生成:链接的规则是规则有序的,适用于一个有序的列表,例如:https://example.com/some_content?page=1
- 无序/规则 -> 发现:从上一次请求的响应中抽取链接,例如详情页的链接可以从列表页抽取。
认证
- 账号获取 -> 自动注册:通过接收验证码的平台,识别验证码的平台做自动的账号处理
加解密
- 密钥获取 -> 客户端反编译
内容抽取
- html页面 -> JsoupXpath
- json响应 -> JsonXpath
应对反爬
- 切换请求IP -> 拨号vps
- 切换User-Agent
- 切换账号
- 控制请求频率
一个好的爬虫
我心目中一个好的爬虫:
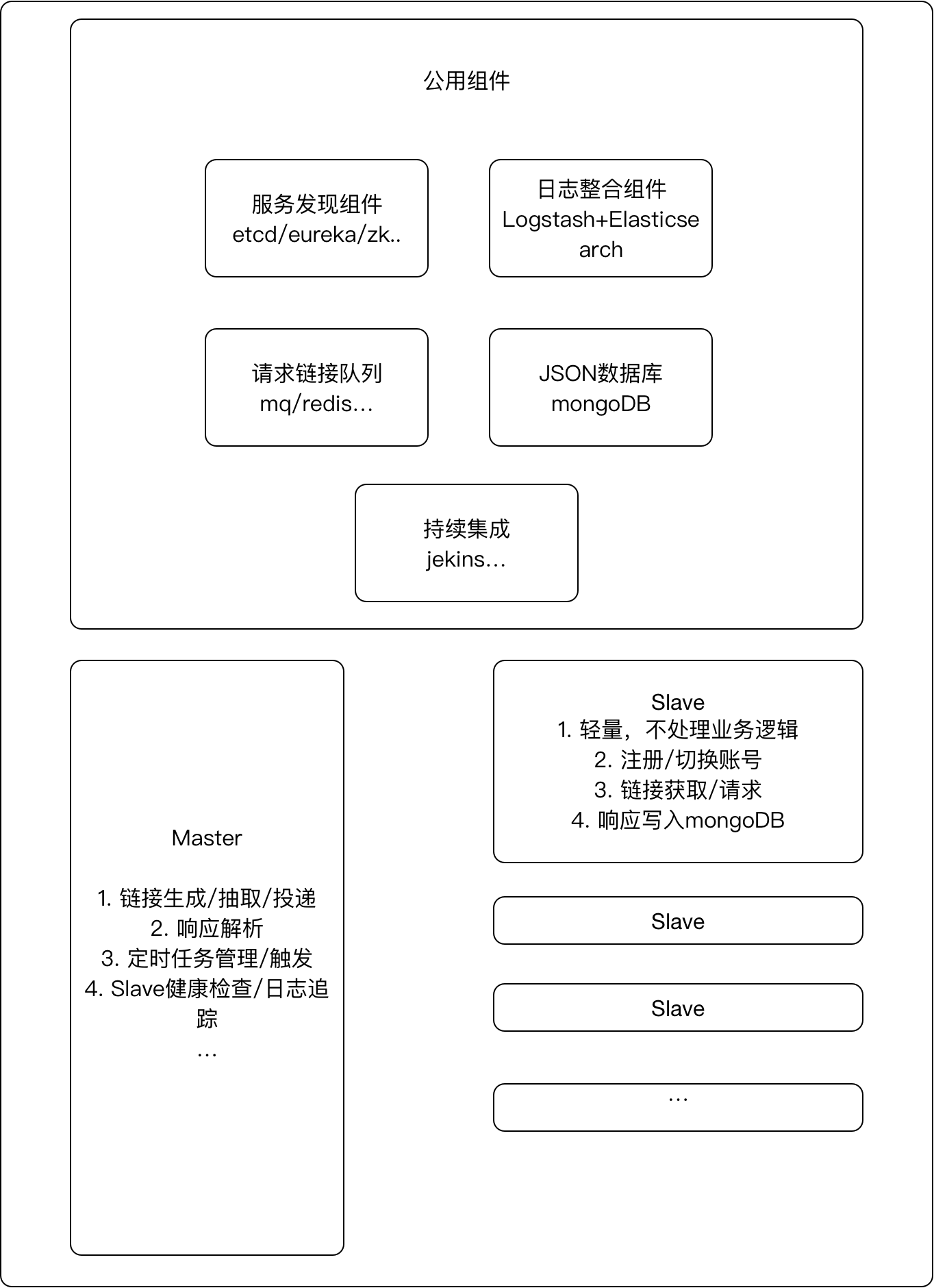
服务发现
使用etcd来记录slave的动态IP
日志整合
slave使用rsyslog投递消息到日志中心,日志中心使用logstash提交到es,master通过es获取日志
请求分发
master统一生成链接投递到mq或者redis queue,slave从对应的位置获取任务,根据执行结果修改链接状态
JSON数据库
slave统一将响应写入mongoDB,不做业务逻辑处理,更轻量
jekins持续集成
通过etcd发现爬虫实例,推送最新代码并部署
文章作者 run
上次更新 2017-08-11