一次线上Memory Leak的排查
文章目录
很久很久没有更新博客了,最近遇到了一个线上内存泄露问题,简单记录一下排查的过程。
很早前就有小伙伴反馈调用我们的一个应用响应非常慢,往往更新到最新的部署代码之后就恢复正常了,所以一直没有重视这个问题。这次出现用户反馈,严重影响了正常业务。 现象是:
- 应用响应时间非常长(17s):
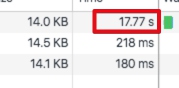
- CPU使用率非常高,JAVA进程的CPU占用在200%以上;
- 应用日志正常,没有任何报错信息。
怀疑是GC导致的问题,先快速通过jstat查看GC的情况:
|
|
返回如下:
|
|
老年代空间已经打满,一直在做FULL GC,但是没有空间得到回收。
各个属性分别指:
| k | v |
|---|---|
| S0C | 年轻代中第一个survivor(幸存区)的容量 (字节) |
| S1C | 年轻代中第二个survivor(幸存区)的容量 (字节) |
| S0U | 年轻代中第一个survivor(幸存区)目前已使用空间 (字节) |
| S1U | 年轻代中第二个survivor(幸存区)目前已使用空间 (字节) |
| EC | 年轻代中Eden(伊甸园)的容量 (字节) |
| EU | 年轻代中Eden(伊甸园)目前已使用空间 (字节) |
| OC | Old代的容量 (字节) |
| OU | Old代目前已使用空间 (字节) |
| PC | Perm(持久代)的容量 (字节) |
| PU | Perm(持久代)目前已使用空间 (字节) |
| YGC | 从应用程序启动到采样时年轻代中gc次数 |
| YGCT | 从应用程序启动到采样时年轻代中gc所用时间(s) |
| FGC | 从应用程序启动到采样时old代(全gc)gc次数 |
| FGCT | 从应用程序启动到采样时old代(全gc)gc所用时间(s) |
| GCT | 从应用程序启动到采样时gc用的总时间(s) |
| NGCMN | 年轻代(young)中初始化(最小)的大小 (字节) |
| NGCMX | 年轻代(young)的最大容量 (字节) |
| NGC | 年轻代(young)中当前的容量 (字节) |
| OGCMN | old代中初始化(最小)的大小 (字节) |
| OGCMX | old代的最大容量 (字节) |
| OGC | old代当前新生成的容量 (字节) |
| PGCMN | perm代中初始化(最小)的大小 (字节) |
| PGCMX | perm代的最大容量 (字节) |
| PGC | perm代当前新生成的容量 (字节) |
| S0 | 年轻代中第一个survivor(幸存区)已使用的占当前容量百分比 |
| S1 | 年轻代中第二个survivor(幸存区)已使用的占当前容量百分比 |
| E | 年轻代中Eden(伊甸园)已使用的占当前容量百分比 |
| O | old代已使用的占当前容量百分比 |
| P | perm代已使用的占当前容量百分比 |
| S0CMX | 年轻代中第一个survivor(幸存区)的最大容量 (字节) |
| S1CMX | 年轻代中第二个survivor(幸存区)的最大容量 (字节) |
| ECMX | 年轻代中Eden(伊甸园)的最大容量 (字节) |
| DSS | 当前需要survivor(幸存区)的容量 (字节)(Eden区已满) |
| TT | 持有次数限制 |
| MTT | 最大持有次数限制 |
进一步拉了GC日志下来,通过GCEasy分析了一下:
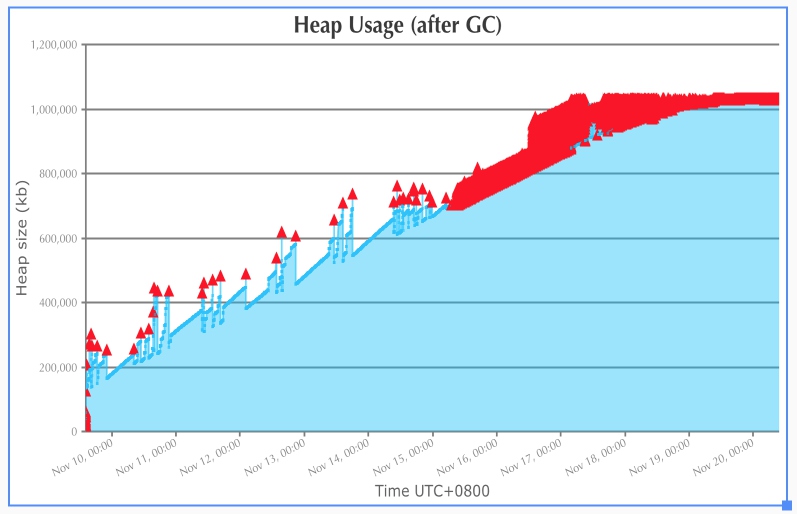
可以看到Full GC后的堆空间一直在持续增长(理想情况下,这个值应该是稳定的),到了Nov 19之后,一直在持续进行Full GC,却无法回收足够的堆空间,导致应用吞吐量急剧下降,CPU资源都在做GC操作。 内存无法被垃圾回收,显然存在内存泄露,内存泄露大致有两种情况:
- 新生代内存泄露导致频繁触发Young GC
- 老年代内存泄露导致频繁触发Full GC
内存泄露一般通过分析内存dump中的对象占用空间来判断,由于内存dump的同时会自动触发一次Full GC,内存泄漏体现在Full GC无法回收的内存对象中,所以可以直接通过内存dump进行分析。
内存dump的一般方式是通过jmp命令:
|
|
- 一般要传递
live参数来指定只捕获存活的对象 - 获取进程号可以通过jdk中的
jps或者系统ps命令 - 如果应用是docker应用,要进入docker容器中(docker exec -it docker镜像id bash)操作,直接在宿主机中执行
jmap命令会返回Error attaching to core file: cannot open binary file异常
获取到dump文件之后通过Eclipse的Memory Analyzer打开(如果dump文件较大,记得先编辑配置文件中的启动jvm参数mat.app/Contents/Eclipse/MemoryAnalyzer.ini),选择分析可能的内存泄露(Leak Suspects Report),会将占用的空间最多的对象列举出来:

可以看到CommonMessageConsumer持有的ConcurrentSkipListMap占用了69.37%的堆空间。
下面是代码片段:
|
|
代码维护了一个去重Set,Set又是通过Map实现的,所以随着Set中内容增长,堆空间会被逐渐耗尽。
jvm参数配置
Concurrent Mode Failure
由于内存在4G以上,所以一般采用CMS回收机制,CMS有一个特有的GC原因:Concurrent Mode Failure,如果这个原因触发的GC占很大比重,就需要通过启用UseCMSInitiatingOccupancyOnly并调低CMSInitiatingOccupancyFraction提前触发GC来避免Full GC。
Promotion Failure
在CMS中,老年代采用的是标记-清除算法,会导致老年代空间逐渐碎片化,新生代晋升的时候如果老年代没有足够的连续空间来存放,就会触发Full GC。为了缓解这个问题,可以通过启用UseCMSCompactAtFullCollection并定义CMSFullGCBeforeCompaction来指定若干次的清除之后进行一次整理操作。
GC 日志配置
一般要配置UseGCLogFileRotation来滚动GC日志。
|
|
文章作者 run
上次更新 2017-11-24