回顾历史
直到今天,卖好车App的搜索依然采用的是阿里云的opensearch,先来说说使用过程中的痛点。
阿里云OpenSearch的痛点
收费
索引自创建完成就开始计费,就算或者没有新数据需要进入索引,依然在被收费。
重建索引的速度非常慢
1W条记录,每条记录5个20字符以内字段,重建一次索引需要半个小时。
黑盒,不可见,不可控
分词的不可控
分词是搜索中最重要的一个环节,在索引创建和搜索关键词的产生中都起了决定性的作用。
但是OpenSearch没有提供接口返回分词的结果,也没有文档解释分词原理,我们输入了一个词,只能期待他能返回我们想要的结果,但是往往并不是。
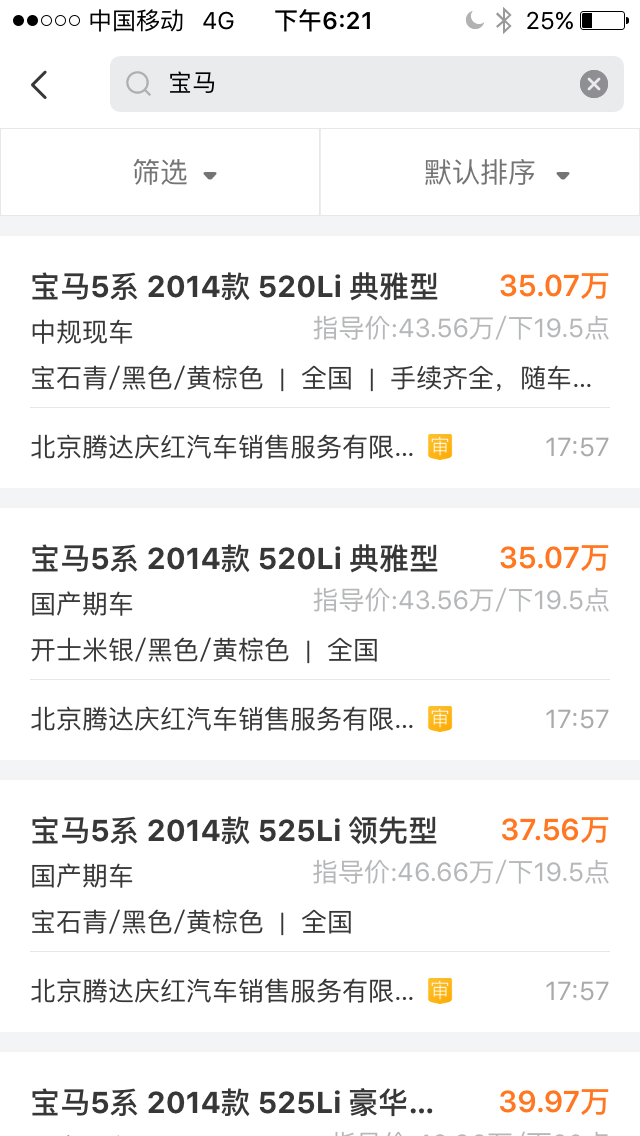
比如输入北京宝达,OpenSearch替我们做了一些分词之后出来的结果如下:
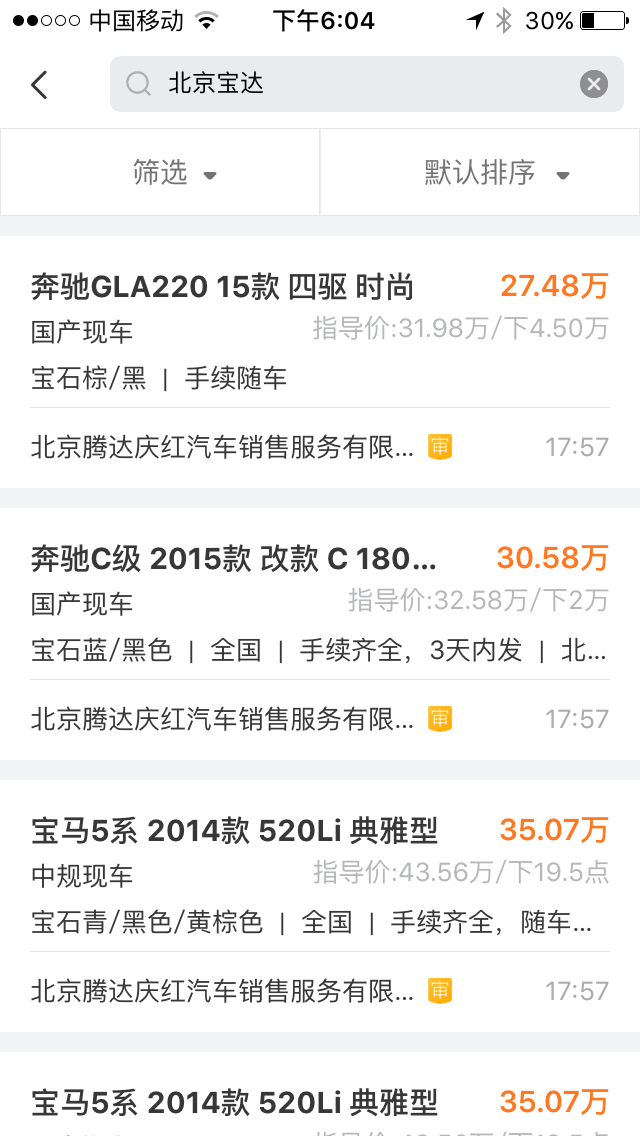 但是我们想要搜的
但是我们想要搜的北京宝达这家公司在20条之后才出现。我们无法控制OpenSearch不对宝达这两个字不要分词。
不支持同义词,无法自定义停用词
同义词顾名思义,我搜索番茄,应该把西红柿也返回给我,我搜索拓爷,应该把黄拓也返回给我,在车系里面比较典型的例子是霸道和普拉多。

但是OpenSearch并不支持同义词的配置。
停用词是类似语气词【啊,哦,啦】,介词【从,在,跟,】等等无语意需要在分词的过程中过滤的词语,但是很遗憾OpenSearch并没有告诉我们哪些被他过滤了,我们也无法自己添加需要的过滤词语。
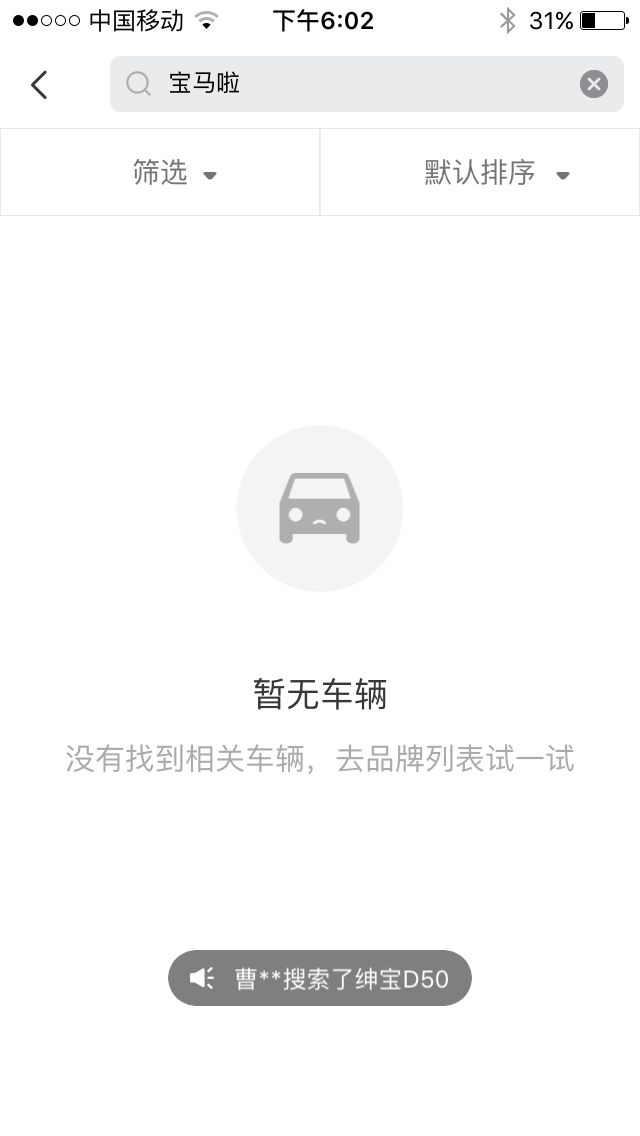
检索方式的不可控
OpenSearch对搜索默认进行了分词,但必须全部都匹配才返回搜索结果。如果我想要分词结果中任一条匹配即返回,OpenSearch是无法满足的。
以上的组合会带来许许多多错误结果,而且这些错误我们只能猜测,根本无法调试。
举一个比较极端的例子,假如我输入了 宝马北京, OpenSearch替我分词为【宝,马北,京】,而且他的检索规则是这些分词结果都要得到匹配,那么很显然我们得不到我们想要的结果。因为宝马在品牌字段,北京在车源字段,马和北在创建索引时是不可能得到组合的。
返回结果的排序不可控
作为一个商业搜索,用户对于他出现在搜索中的位置是很在意的,但是OpenSearch只能简单的通过字段的升降序方式排序。之前有一个需求是认证商家要展示在非认证商家之前,好,我们通过is_verify这个字段降序排了一把,结果1个月前的一个认证商家的可能是已经无效的车源数据,依然排在辛辛苦苦天天更新车源的一个非认证商家的前面,这个会严重打击商家的活跃积极性。后来我们又改了回来,只能根据更新时间排序,认证商家的车源即使发布时间很接近也会被排在后面。
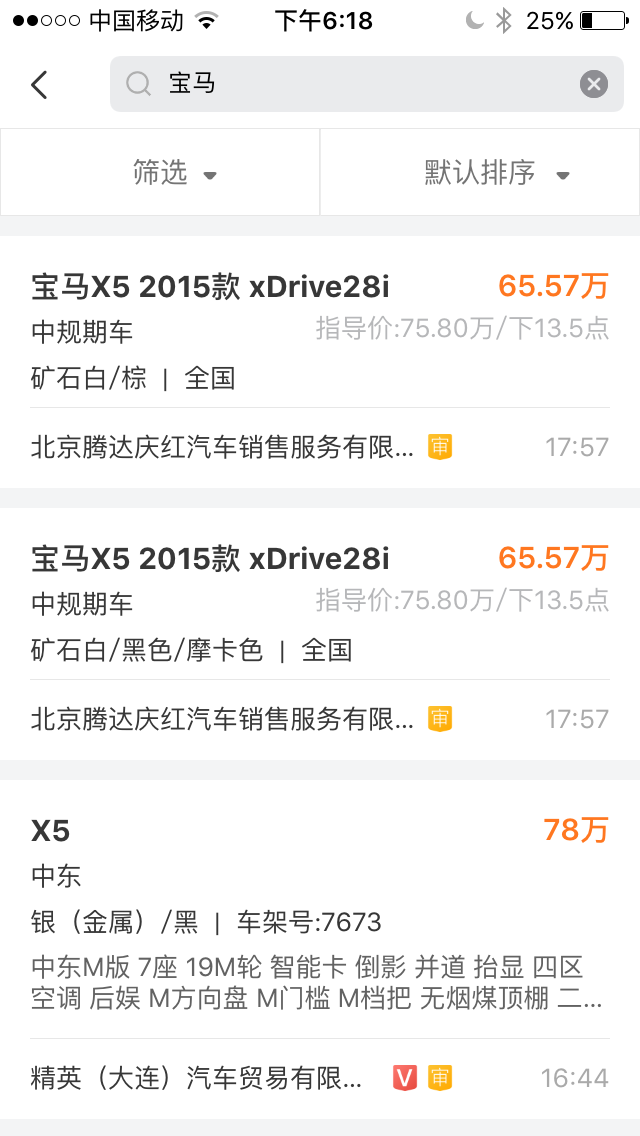 还有一点就是搜索结果的公平性:目前我输入
还有一点就是搜索结果的公平性:目前我输入宝马,结果中出来的前11条都是北京腾达庆红汽车销售服务有限公司的车源,这样对于其他车商显然是不公平的,换句话说,我们应该对提供同一个商品的不同商家在展示结果上做一定程度的打散。
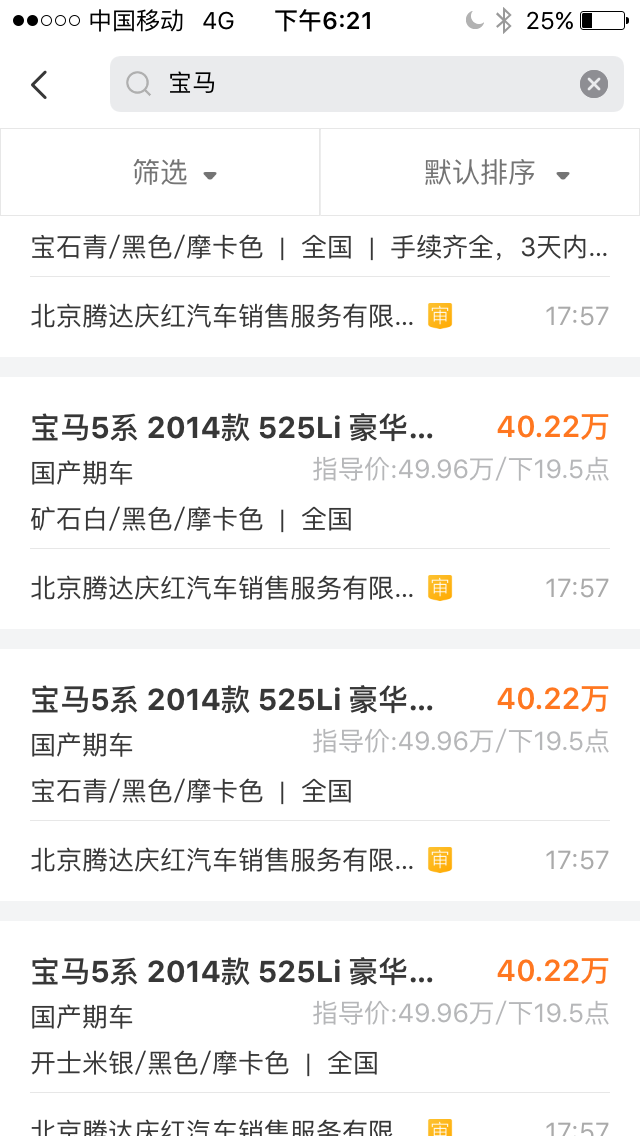
过去做过的努力
同义词
OpenSearch的分词是不可信任的,所以我们在拿到用户输入的关键字之后,先到我们的同义词表进行检索,将匹配上的关键字转为更精确的搜索条件。比如我的同义词表定义了一项:宝马 => brandId=11,用户输入宝马之后,处理之后进入OpenSearch的是brandId为11这个条件。
这个折衷的方案存在很多严重的缺陷:
语义丢失
假如有一家公司名字叫做:杭州红宝马汽车销售有限公司,他们老板输入了红宝马三个字,想要看一下他们公司的车,但是很遗憾,经过我们的同义词,红=>colorId=1,宝马=>brandId=11,进入了OpenSearch,显然这个老板永远也看不到他想要的结果。
再比如之前出现过的一种情况,用户输入奔驰GL,他可能想搜中规的奔驰GL车系,也可能想搜平行进口的奔驰GL400,奔驰GL500等等的奔驰GL开头的车系,由于同义词定义了奔驰GL指向奔驰GL车系,导致用户搜不到平行进口的几个车系的车。
同义词提取问题
默认是通过空格划分提取同义词,但是如果用户输入的若干关键字未通过空格划分,会导致同义词完全匹配不上。
比如输入霸道红,可以看到虽然后台配置了霸道与普拉多是同义词,但是用户输入时没有通过空格分隔,这里并没有出来普拉多。

维护同义词成本
根据车系总量是1600条左右,车系的同义词就需要大于1600条,再加上颜色,区域,车规的同义词,同义词的数量对于人肉处理来说已经很庞大了(目前是2500条左右),出现新的意外情况都需要通过同义词排查,维护同义词。

检索效率
用户输入的一个词,我们通过猜测,将这个词转换成了多个词或者多个查询条件,很影响查询的效率。
比如用户输入了宝马5,我们可能就需要把查询条件转化为:宝马x5 || 宝马x5(平行进口) || 宝马5系 || 宝马m5 || 宝马x5 m ….
目前我们是有200多条同一个关键词匹配多条记录的同义词,最多的有十几条:

总的来说,我们想方设法在逻辑层修修补补,而OpenSearch扮演的角色充其量是一个首尾模糊like查询速度比较快的mysql而已。
Elasticsearch
Elasticsearch是一个基于Lucene的开源,分布式全文检索引擎。Github
基本的概念
倒排索引 : inverted indexing
Lucene采用倒排索引(inverted indexing)的方式创建索引。
例如,每一篇文章都包含若干tag,通过反向创建索引,如果需要找出包含某个tag的文章,就无需遍历所有文章进行寻找。

相关度计算 : TF/IDF
Elasticsearch采用TF/IDF来计算文档与查询内容的的相关度。TF/IDF指的是term frequency–inverse document frequency,即出现频度-在倒排索引中的频度。可以简单的认为,查询关键字在一个文档中出现的次数越多,而且这个关键字在全部结果中出现的次数越少,这个文档的相关性就越强。
TF很直观就不解释了,IDF这个也不难理解,他表示一个在所有文档中出现次数越少的词,越有助于我们定位用户想要的查询结果。
好比你到一家鱼铺去买鱼,你跟老板说你要一条鱼,他根本不知道你想要的是什么,因为几乎所有的鱼名字都带有鱼,即鱼在所有记录中出现的次数很多。但如果你跟老板说你要一条鲫鱼,老板马上就会给你捞一条鲫鱼,因为鲫这个字在记录中只出现了一次,这个词的匹配理应给这个记录带来很高的加分。
再举个例子:
比如搜索宝马 x6,所有的结果中,x6出现的概率较小,包含x6的结果得分会比包含宝马的得分要高。
查询结果的得分解释中有关的x6的显示:
6.0730667 = idf(docFreq=673, maxDocs=107613)
即x6这个词在全部107613个文档中出现了673次,IDF得分是6.0730667。
而有关宝马的部分显示:
4.177803 = idf(docFreq=4484, maxDocs=107613)
即x6这个词在全部107613个文档中出现了4484次,IDF得分是4.177803。

Elasticsearch还给我们提供了很多方式来影响某条记录的最终得分从而影响结果的展示顺序,后面我们会具体讲到。
显著的提升
历史中的问题在Elasticsearch中都得到了比较完美的解决。
索引创建速度


如图所示,20W条记录,每条记录包含55个字段,从创建数据库连接到索引建立完成,耗时不到3分钟。
准实时查询
添加到索引的记录可以实时被检索到。
目前采用的方式是通过elasticsearch-jdbc每隔10s从mysql中拉一次数据(是否采集通过gmt_modify判断),同步到elasticseach的索引中,所以一条记录从产生到可以响应查询的延时最差情况下是10s + mysql查询耗时 + elasticsearch创建耗时 + 网络传输耗时,一般不会超过15s。

存在的问题:
- 需要定时轮询
- 对时间准确的依赖
- 多数据源的配置很麻烦
- 实时性不够完美
更好的方式:

图片 from 卢栋@杭州码耘网络 Elasticsearch-jdbc介绍及基于binlog增量同步方案
准确,可控的分词
在Elasticsearch中,这个过程称为Analyze,我们平时说的分词其实只涵盖了其中的Tokanizer部分,这里姑且用Elasticsearch分词来指代一下整个Analyze过程。
Elasticsearch分词的整个过程如下:

包含了多个character filter -> 一个tokenizer -> 多个token filter。
其中:
character filter在文档被进行分词之前对文档进行处理,官方定义了3个character filter,包含html字符的转义,根据正则替换特定字符,根据映射替换字符。
tokenizer就是我们常说的分词了,用于将文档转为一个个token,这些token会被通过上文中的inverted indexing的方式创建索引。
token filter用于分词器产生的token的处理,如添加同义词,过滤停用词,更细粒度划分等等。官方提供了许多非常实用的实现 :analysis-tokenfilters。
在这一步我们做了许多的优化,主要包含了:
同义词
注意这里的同义词的概念与之前很不一样。
原来的同义词是在搜索的时候处理关键字:

现在我们通过定义不同的Elasticsearch分词过程,只在添加索引记录时处理同义词:

更好的方案:
不仅在创建索引时添加同义词,而且根据用户的查询分析,在用户检索时添加同义词并赋予权重:

图片 from 洪斌@有赞 :有赞搜索引擎实践
词库维护
在词库里面定义的词条,在分词过程中会被拆分为一个token,这样处理可以避免一些不必要的拆分导致搜索出现意外的结果。
比如我们定义宝马为一个词条,在查询的过程中,宝马不会被进一步拆分为宝和马,从而搜出来宝奥马汽车销售有限公司这种结果。
但是过多这样处理也是有风险的,比如我们定义了一条x6 m的词条,搜索的时候分词成x6 m,导致搜不出来宝马X6 16款 3.0T M运动这样的车。反而x6m能被分成x6和m,从而可以搜到这辆车。
目前我们定义的同义词包含常用词约40W条,自定义词条:品牌名,车系名,车系名中去除品牌名的部分(负面效果比较大,打算去掉),省市县3级名称,车规名,内饰、外观颜色名,年款 共约1w条。
停用词
对分词产生的结果进行过滤,目前主要过滤了空格,色等。
指导价寻车
需求是根据指导价的4位数字获取匹配指导价,比如:用户输入2486,需要匹配到指导价为24.86万的车,输入1110,需要匹配到指导价为11.1万的车。处理的方法是添加了两个根据正则匹配的token filter:
1
2
3
4
5
6
7
8
9
|
char_filter :
price_patern :
type: pattern_replace
pattern: (\d{1,4})\.(\d{1,2})万
replacement: $1$2
price_patern2:
type: pattern_replace
pattern: (\d{1,4})\.(\d{1})万
replacement: $1 $2 0
|
排序的优化
在对查询结果进行排序的时候,已经不再是简单的存在与否的问题,而是查询结果与查询条件之间有多相关的问题。
Elasticsearch中的相关度基于score来衡量。
TF :Term Frequency
关键字在某个文档出现的次数越多,得分越高:

实际的计算公式为 : tf(t in d) = √frequency
IDF : Inverse Document Frequency
某个关键字在全部文档中出现的次数越多,他的TF得分的权重就越低。
比如在下面3句话中搜索 the elasticsearch:

假如没出现一次计1分,如果不考虑IDF,每句话的TF得分都是一样的 2 分。
通过Inverse Document计算IDF :
1
2
3
|
Token | Sentence | IDF
the | 1,2,3 | 3
elasticsearch | 1,2 | 2
|
计算IDF后,第一句话的得分与第二句话的得分一致:1/2 + 1/3 = 5/6,第三句话的得分是2/3。
实际的计算公式为 : idf(t) = 1 + log ( numDocs / (docFreq + 1))
field-length norm
字段长度归约,同一个文档中存在的总token数量越少,匹配到查询token的得分就越高。
实际的计算公式为:norm(d) = 1 / √numTerms
TF/IDF
lucene基于TF/IDF的score计算公式如下 :
score(q,d) = queryNorm(q) · coord(q,d) · ∑ (tf(t in d) · idf(t)² · t.getBoost()· norm(t,d) ) (t in q)
practical-scoring-function
当然你还可以指定其他的相关度计算方法:
- Okapi BM25
- Divergence from randomness, or DFR similarity
- Information based, or IB similarity
- LM Dirichlet similarity
- LM Jelinek Mercer similarity

通过给字段设置boost影响score
现有的查询是到多个字段中寻找匹配的。
比如我们搜索北京,北京这个关键字同时存在于品牌,车系,车型,厂商,车源所在地等字段中,如果我们想让品牌匹配上北京的结果出现在靠前的位置,我们可以通过给品牌这个字段设置一定的查询时提升(boost)。
代码:

explain:

function score query
除了通过boost影响文本相关度的得分,我们还可以通过自定义函数的形式影响最终的得分,elsticsearch为我们提供了function score query来自定义我们的函数:function-score-query。
认证商家的提升
如果一条车源是认证商家发布的,is_verify字段为1,否则为0。
通过fieldValueFactorFunction来处理is_verify字段,将这个字段的值作为函数的输入:
1
2
3
4
|
FieldValueFactorFunctionBuilder verifyScore = ScoreFunctionBuilders.fieldValueFactorFunction("is_verify");
verifyScore.factor(1.5f);// 字段的值乘上1.5
verifyScore.missing(0);// 若字段为空返回0
verifyScore.setWeight(getRedisOrDefault(WeightEnum.VERIFY.getKey(), 1));// 设置权重
|
是否手工发布的处理
如果一条车源是手工发布发布的,is_induce字段为0,否则为1。
通过定义一个线性函数(inear)来处理is_induce字段:
函数:

代码:
1
2
|
LinearDecayFunctionBuilder induceScore = ScoreFunctionBuilders.linearDecayFunction("is_induce", 0, 1);
induceScore.setWeight(getRedisOrDefault(WeightEnum.INDUCE.getKey(), 1));
|
结果就是输入0返回1,输入1返回0。
是否电议也是同样的处理方式。
更新时间的处理
更新时间的处理就不是单纯的线性关系,而更像一个梯形的函数:

一天内发布的车源得分0.6,一天以外的的车源得分以0.6的速度衰减:
1
2
3
4
|
LinearDecayFunctionBuilder updateDateScore = ScoreFunctionBuilders.linearDecayFunction("modify","1d");
updateDateScore.setOffset("2d");
updateDateScore.setDecay(0.6);
updateDateScore.setWeight(getRedisOrDefault(WeightEnum.DATE.getKey(), 1));
|
结果打散
通过random_score来获取一个随机的分数,这个分数可以基于一个特定的数字(用户的sessionid)产生,确保同一个session获取的随机分是一致的,不会出现翻页后结果错乱的问题。
组合
function score设置的多个函数的结果可以通过下列形式进行组合(score_mode):
1
2
3
4
5
6
7
|
运算符| 操作
multiply | (默认)得分进行乘积运算
sum | 求和
avg | 平均
first | 取第一个函数结果
max | 取最大
min | 取最小
|
组合的时候可以通过设置weight权重来控制每个函数对结果的影响。
function score的最终结果可以通过下列形式组合到TF/IDF得分上(boost_mode):
1
2
3
4
5
6
7
|
运算符| 操作
multiply | (默认)得分进行乘积运算
replace | 仅使用function score query的得分,忽略TF/IDF得分
sum | 求和
avg | 平均
max | 取最大
min | 取最小
|
目前采用的方式是:score_mode=sum,boost_mode=multiply,主要基于以下考虑:
- 我们自定义function中存在输出为0的函数,比如控制
is_verify的函数,如果函数之间的组合采用乘积的形式会抹去其他函数的作用,所以使用求和方式比较合适。
- 相关度的得分没有做归一化处理,分散在0~10之间,所以与function score query的得分进行组合使用乘积比较合理。
读懂得分
以下是输入宝马 中规出来结果第一条的得分:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
1.7160147 = function score, product of:
0.8580074 = sum of:
0.8580074 = sum of:
0.36771744 = max of:
0.18385872 = weight(model_name:宝马 in 30025) [PerFieldSimilarity], result of:
0.18385872 = score(doc=30025,freq=1.0), product of:
0.23471184 = queryWeight, product of:
2.0 = boost
4.177803 = idf(docFreq=4484, maxDocs=107613)
0.028090343 = queryNorm
0.78333807 = fieldWeight in 30025, product of:
1.0 = tf(freq=1.0), with freq of:
1.0 = termFreq=1.0
4.177803 = idf(docFreq=4484, maxDocs=107613)
0.1875 = fieldNorm(doc=30025)
0.36771744 = weight(series_name:宝马 in 30025) [PerFieldSimilarity], result of:
0.36771744 = score(doc=30025,freq=1.0), product of:
0.23471184 = queryWeight, product of:
2.0 = boost
4.177803 = idf(docFreq=4484, maxDocs=107613)
0.028090343 = queryNorm
1.5666761 = fieldWeight in 30025, product of:
1.0 = tf(freq=1.0), with freq of:
1.0 = termFreq=1.0
4.177803 = idf(docFreq=4484, maxDocs=107613)
0.375 = fieldNorm(doc=30025)
0.49028993 = max of:
0.49028993 = weight(spec_name:中规 in 30025) [PerFieldSimilarity], result of:
0.49028993 = score(doc=30025,freq=1.0), product of:
0.23471184 = queryWeight, product of:
2.0 = boost
4.177803 = idf(docFreq=4484, maxDocs=107613)
0.028090343 = queryNorm
2.0889015 = fieldWeight in 30025, product of:
1.0 = tf(freq=1.0), with freq of:
1.0 = termFreq=1.0
4.177803 = idf(docFreq=4484, maxDocs=107613)
0.5 = fieldNorm(doc=30025)
0.0 = match on required clause, product of:
0.0 = # clause
0.028090343 = #is_deleted: � #sku_status: ��, product of:
1.0 = boost
0.028090343 = queryNorm
2.0 = min of:
2.0 = function score, score mode [sum]
0.0 = function score, product of:
1.0 = match filter: *:*
0.0 = product of:
0.0 = field value function: none(doc['is_verify'].value?:0.0 * factor=1.5)
0.0 = weight
0.0 = function score, product of:
1.0 = match filter: *:*
0.0 = product of:
0.0 = Function for field modify:
0.0 = max(0.0, ((2.16E8 - MIN[Math.max(Math.abs(1.46647956E12(=doc value) - 1.466928806432E12(=origin))) - 1.728E8(=offset), 0)])/2.16E8)
1.0 = weight
1.0 = function score, product of:
1.0 = match filter: *:*
1.0 = product of:
1.0 = Function for field is_dianyi:
1.0 = max(0.0, ((2.0 - MIN[Math.max(Math.abs(0.0(=doc value) - 0.0(=origin))) - 0.0(=offset), 0)])/2.0)
1.0 = weight
1.0 = function score, product of:
1.0 = match filter: *:*
1.0 = product of:
1.0 = Function for field is_induce:
1.0 = max(0.0, ((2.0 - MIN[Math.max(Math.abs(0.0(=doc value) - 0.0(=origin))) - 0.0(=offset), 0)])/2.0)
1.0 = weight
3.4028235E38 = maxBoost
|
筛选功能的优化
筛选条件的获取
目前我们获取筛选条件的方式是通过select distinct()的方式。
比如搜索宝马,如果想要获取搜索结果中所有的车规种类,需要进行一次select distinct(spec) from table where keyword='宝马'查询。
每次查询都需要额外对 车规, 车系, 外观颜色 字段分别做一次select distinct查询,才能获取所有的筛选条件。
elasticsearch为我们提供了聚合(aggregation)功能,可以在返回查询结果的同时,返回指定字段(可多个)的所有聚合结果。
如选择车规和外观颜色进行聚合:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
POST /car4/car/_search
{
"query": {
"match_all": {
}
},
"size": 1,
"aggs": {
"spec": {
"terms": {
"field": "spec_name.raw",
"size": 2
}
},
"color" : {
"terms": {
"field": "outer_color_name.raw",
"size": 2
}}
}
}
|
查询结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
|
{
"took": 21,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"hits": {
"total": 201211,
"max_score": 1,
"hits": [
{
"_index": "car4",
"_type": "car",
"_id": "282884",
"_score": 1,
"_source": {
"car_id": 282884,
"seller_id": 32,
"series_name": null,
"model_name": null,
"custom_model": "17款 GLS450",
"inner_color_name": "黑",
"outer_color_name": "黑",
"send_city": null,
"seller_price": 115000000,
"corp_name": "精英(大连)汽车贸易有限公司",
"spec_name": "平行进口",
"spec": 7,
"is_induce": 1,
"is_verify": 1,
"modify": "2016-05-30T21:24:56.000+08:00",
"gmt_create": "2016-05-12T19:55:46.000+08:00",
"price_adjust_way": 1,
"inner_color_id": -1,
"outer_color_id": -1,
"car_source": 0,
"car_type": 3,
"series_id": 2002,
"brand_id": 14,
"model_id": -1,
"configure": "17款,大窗,P01,19轮,防盗螺丝,氙灯,灰色顶篷,二排易入,照明脚踏,后娱预留,车道包,停车辅助包",
"car_area": null,
"car_status": "2016/7/30预计到港",
"reach_date": null,
"formalities_status": null,
"sku_status": 1,
"invoice_price": null,
"car_unique": "7615",
"img_url": null,
"benchmark": null,
"fuel": 1,
"quantity": 1,
"insurance": null,
"remark": null,
"sanbao": null,
"custom_formality": null,
"custom_area": null,
"config_price": null,
"by_template": 0,
"price_adjust_val": "-1",
"is_dianyi": 0,
"ext_id": null,
"creator": 78,
"guide_price": null,
"guide_price_na": null,
"is_deleted": 1,
"send_city_pre": null
}
}
]
},
"aggregations": {
"color": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 97885,
"buckets": [
{
"key": "白",
"doc_count": 54875
},
{
"key": "黑",
"doc_count": 48376
}
]
},
"spec": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 55099,
"buckets": [
{
"key": "中规",
"doc_count": 121437
},
{
"key": "国产",
"doc_count": 24675
}
]
}
}
}
|
筛选条件的构建
限于目前客户端的显示,查询条件需要通过后台返回id+name的形式来构建查询条件,但是如果通过聚合来实现筛选,只能返回聚合字段的值。
比如要创建车规的筛选条件,就需要通过车规id(spec_id)或者车规名字(spec_name)来进行聚合。如果通过车规id(spec_id)来聚合,返回的结果就是:
1
2
3
|
spec_id=1,count=10;
spec_id=2,count=20;
...
|
这样的结果,如果通过车规名字(spec_name)来聚合,同样只能返回以spec_name划分的数量。如果我同时需要id和name,就需要自己再进行翻译处理。
在客户端逻辑不变的前提下,想出了一种解决的方式:每次聚合的同时取一条tophit,以这条tophit的id或者name来构建筛选条件。
查询条件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
POST /car4/car/_search
{
"query": {
"match_all": {
}
},
"size": 1,
"aggs": {
"spec": {
"terms": {
"field": "spec_name.raw",
"size": 2
},
"aggs": {
"top_tag_hits": {
"top_hits": {
"sort": [
{
"spec": {
"order": "desc"
}
}
],
"_source": {
"include": [
"spec"
]
},
"size" : 1
}
}
}
}
|
返回结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
|
{
"took": 19,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"hits": {
"total": 201211,
"max_score": 1,
"hits": [
{
"_index": "car4",
"_type": "car",
"_id": "282884",
"_score": 1,
"_source": {
"car_id": 282884,
"seller_id": 32,
"series_name": null,
"model_name": null,
"custom_model": "17款 GLS450",
"inner_color_name": "黑",
"outer_color_name": "黑",
"send_city": null,
"seller_price": 115000000,
"corp_name": "精英(大连)汽车贸易有限公司",
"spec_name": "平行进口",
"spec": 7,
"is_induce": 1,
"is_verify": 1,
"modify": "2016-05-30T21:24:56.000+08:00",
"gmt_create": "2016-05-12T19:55:46.000+08:00",
"price_adjust_way": 1,
"inner_color_id": -1,
"outer_color_id": -1,
"car_source": 0,
"car_type": 3,
"series_id": 2002,
"brand_id": 14,
"model_id": -1,
"configure": "17款,大窗,P01,19轮,防盗螺丝,氙灯,灰色顶篷,二排易入,照明脚踏,后娱预留,车道包,停车辅助包",
"car_area": null,
"car_status": "2016/7/30预计到港",
"reach_date": null,
"formalities_status": null,
"sku_status": 1,
"invoice_price": null,
"car_unique": "7615",
"img_url": null,
"benchmark": null,
"fuel": 1,
"quantity": 1,
"insurance": null,
"remark": null,
"sanbao": null,
"custom_formality": null,
"custom_area": null,
"config_price": null,
"by_template": 0,
"price_adjust_val": "-1",
"is_dianyi": 0,
"ext_id": null,
"creator": 78,
"guide_price": null,
"guide_price_na": null,
"is_deleted": 1,
"send_city_pre": null
}
}
]
},
"aggregations": {
"spec": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 55099,
"buckets": [
{
"key": "中规",
"doc_count": 121437,
"top_tag_hits": {
"hits": {
"total": 121437,
"max_score": null,
"hits": [
{
"_index": "car4",
"_type": "car",
"_id": "284668",
"_score": null,
"_source": {
"spec": 1
},
"sort": [
1
]
}
]
}
}
},
{
"key": "国产",
"doc_count": 24675,
"top_tag_hits": {
"hits": {
"total": 24675,
"max_score": null,
"hits": [
{
"_index": "car4",
"_type": "car",
"_id": "262165",
"_score": null,
"_source": {
"spec": 0
},
"sort": [
0
]
}
]
}
}
}
]
}
}
}
|
筛选的实现
在查询时添加fllter:
1
2
3
4
5
6
7
8
9
|
"filter": {
"bool": {
"must": {
"term": {
"is_deleted": "0"
}
}
}
}
|
代码:
1
2
3
4
5
|
BoolQueryBuilder innerBool = QueryBuilders.boolQuery();
innerBool.must(QueryBuilders.termQuery("is_deleted", 0));
BoolQueryBuilder filteredQueryuery = QueryBuilders.boolQuery();
filteredQueryuery.filter(innerBool);
filteredQueryuery.must(mqb);
|
infiniti : the future
实时添加索引
cannel,rocketMQ(ONS,kafuka),otter
定时重建索引
通过alias无缝切换
同义词和词典的维护
redis,http
备份和恢复
nas
数据分析
hadoop,spark,hive,Hbase