分布式系统设计迷思
文章目录
先祭出祖师爷:

You want proff?I’ll give you proff! - Leslie Lamport
单机系统
小强的这家咖啡店刚开始经营,为了让顾客满意,他想需要记住每个顾客喜欢的咖啡,比如万剑喜欢摩卡,拓爷喜欢星冰乐等等,每次顾客进来,马上就能给顾客想要的咖啡。 简单起见,小强拿了一个本子,上面记录着顾客的喜好信息:
|
|
…
只需要单机系统的日子是美好的。
简单的分布系统
小强经营有方,咖啡店的生意慢慢好了起来,为了减少顾客的排队时间,小强招了另外两个店员:小白和小黑。 这时候,怎么让小白和小黑也能知道顾客喜欢哪种咖啡呢?
小白提了个建议:
复制读取:Read Replication
顾客想要添加或者修改喜欢的咖啡需要找小强统一维护,同时小白和小黑持有小强手上版本的副本。
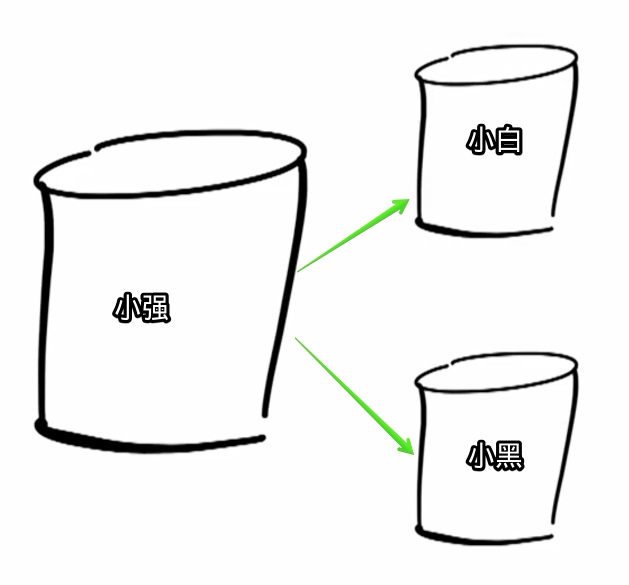 很好,这样小白和小黑都能知道顾客喜欢哪种咖啡了,而且可以接收以前3倍的用户读取请求。
但是这样做有什么问题呢?
很好,这样小白和小黑都能知道顾客喜欢哪种咖啡了,而且可以接收以前3倍的用户读取请求。
但是这样做有什么问题呢?
- 复杂性:顾客必须找小强才能维护自己喜欢的咖啡,小强得到信息后必须确保小白和小黑得到更新。
- 一致性:很难保证小白和小黑手上持有的版本与小强一直保持一致。乐观的看,这需要一定的延时。如果小强给小白发了一条消息,但是因为通信的故障小白没有收到,也会导致小白手上的名单出现不一致。
小黑也提了一个建议:
分片:Sharding
通过顾客名字首字母分片,每个人负责维护一部分顾客。
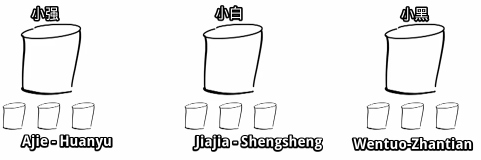
也很好,这样解决了小白方法中的问题,每个顾客只要去找对应咖啡师就行了。 但是这样做也存在了一些问题:
- 复杂性:在顾客和咖啡师之间增加了一层用于将顾客引导到对应的咖啡师。
- 模型的限制:每条记录必须对应一个key,如果想要记住一个50岁左右,跛脚,黄头发的美国老人喜欢什么咖啡,这个就没法处理。
- 提取方式的限制:必须通过一个key来提取记录,如果想要统计这个月消费最多的用户,就必须找个每个分片统计一遍再汇总,丧失了分片的意义。
一致性哈希
对传统的分片算法做了优化,在容错性上有了巨大提升。
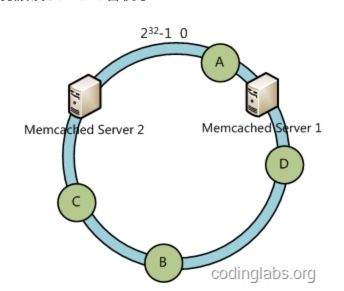
很遗憾,小白和小黑的方法都存在一定缺陷,那小强到底能不能实现一种完美的分布式咖啡店呢?
分布式系统存在的问题
为了实现一个分布式的咖啡店,我们首先考虑一下分布式的系统会为我们带来那些问题。
两军问题
这个问题讨论如果我们没有一个可靠的信道,有没有可能实现一个分布式的系统。
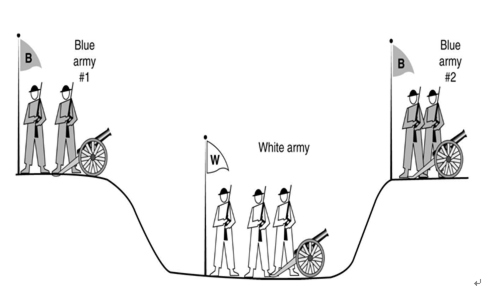 如图1所示,白军驻扎在沟渠里,蓝军则分散在沟渠两边。白军比任何一支蓝军都更为强大,但是蓝军若能同时合力进攻则能够打败白军。他们不能够远程的沟通,只能派遣通信兵穿过沟渠去通知对方蓝军协商进攻时间。是否存在一个能使蓝军必胜的通信协议,这就是两军问题。
如图1所示,白军驻扎在沟渠里,蓝军则分散在沟渠两边。白军比任何一支蓝军都更为强大,但是蓝军若能同时合力进攻则能够打败白军。他们不能够远程的沟通,只能派遣通信兵穿过沟渠去通知对方蓝军协商进攻时间。是否存在一个能使蓝军必胜的通信协议,这就是两军问题。
在这个系统中永远需要存在一个回执,这对于两方来说都并不一定能够达成十足的确信。更要命的是,我们还没有考虑,通信兵的信息还有可能被篡改。由此可见,经典情形下两军问题是不可解的,并不存在一个能使蓝军一定胜利的通信协议。
类比TCP的三次握手协议: 在TCP/IP协议中,TCP协议提供可靠的连接服务,采用三次握手建立一个连接。 第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认; 第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态; 第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。 完成三次握手,客户端与服务器开始传送数据.
而事实上,客户端并不会知道服务器是否收到了k+1;并且,由于信道的不可靠性,j或者k都是可能被截获的,这些问题说明了即使是三次握手,也并不能够彻底解决两军问题,只是在现实成本可控的条件下,我们把TCP协议当作了两军问题的现实可解方法。
拜占庭将军问题
这个问题讨论如果分布式的组建存在可能对其他节点发出破坏性消息的节点,是否能实现一个可用的分布式系统。 拜占庭帝国就是5~15世纪的东罗马帝国,拜占庭即现在土耳其的伊斯坦布尔。我们可以想象,拜占庭军队有许多分支,驻扎在敌人城外,每一分支由各自的将军指挥。将军们只能靠通讯员进行通讯。在观察了敌人以后,忠诚的将军们必须制订一个统一的行动计划。然而,这些将军中有叛徒,他们不希望忠诚的将军们能达成一致,因而影响统一行动计划的制订与传播。问题是:将军们必须有一个算法,使所有忠诚的将军们能够达成一致,而且少数几个叛徒不能使忠诚的将军们做出错误的计划。
采用口头协议,即信道绝对可信,且消息来源可知,若叛徒数少于1/3,则拜占庭将军问题可解。 只要采用了书面协议,即所有消息都可追本溯源,忠诚的将军就可以达到一致。
ACID 和 CAP
事务(transaction)是由一系列对系统中数据进行访问与更新的操作所组成的一个程序执行逻辑单元。
ACID
在写入/更新资料的过程中,为保证事务(transaction)是正确可靠的,所必须具备的四个特性:原子性(atomicity,或称不可分割性)、一致性(consistency)、隔离性(isolation,又称独立性)、持久性(durability)。
CAP理论
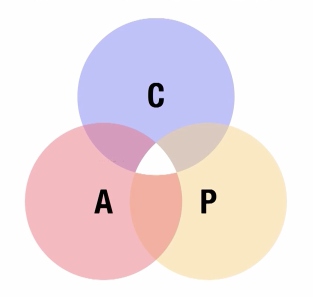 C: Consistency 一致性
A: Availability 可用性
P:Partition Tolerance分区容错性
C: Consistency 一致性
A: Availability 可用性
P:Partition Tolerance分区容错性
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
小强又在隔壁开了一家分店,小花是这家店的店长,为了让顾客在小花的店里也能得到想要的咖啡,小强和小花通过电话来同步顾客的喜好名单。 一致性在这里指的是:顾客在小强店里取到了他喜欢的咖啡,在小花的店里,他拿到的也会是同样的咖啡; 可用性在这里指的是:只要小强或者小花的店开着,就肯定可以为顾客提供他喜欢的咖啡; 分区容错性在这里已经得到了满足,小强和小花是分布的咖啡店。 那这个分布式的咖啡店能否同时又满足一致性又满足可用性呢? 假设小强的手机突然没电了,导致小强和小花之间无法通信,这时候一个顾客找小强更新他喜欢的咖啡,小强帮他更新了他的喜好,但是因为电话没电了无法通知小花,过了一会这个顾客到了小花的店里,因为通信的故障,小花无从得知这个顾客更新了他的喜好,如果要满足可用性,小花必须根据她现有知道的情况(旧的喜好)给顾客提供咖啡,这就破坏了一致性(小强和小花提供的咖啡不同),如果要满足一致性,因为不知道顾客喜欢什么咖啡,小花必须拒绝给顾客提供咖啡,这就破坏了可用性。 所以,在一个分布式的系统当中,我们无法同时满足CAP。
分布式事务解决方案
在分布式系统中,每一个机器节点虽然能够明确知道自己在执行事务操作的过程中是否成功,但却无法直接获取到其他分布式节点的操作结果。因此,当一个事务操作需要跨越多个分布式节点的时候,为了保持事务处理的ACID特性,就需要引入一个“协调者”的组建来统一调度。这些被调度的分布节点称为“参与者”。
2PC
2PC:Two-Phase Commit,即两阶段提交。
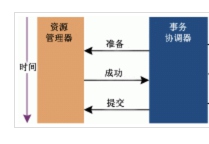
第一阶段:协调者询问参与者是否可以提交事务。如果参与者事务操作执行成功则回复yes,反之no。 第二阶段:参与者都回复yes,协调者发出提交请求,则参与者收到后开始提交事务并释放相关资源。
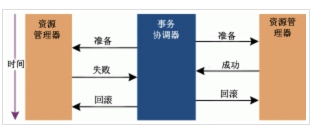 事务中断:加入任何一个参与者反馈了no或者协调者在等待响应时出现超时,都会导致事务中断,协调者向参与者发送rollback请求。
事务中断:加入任何一个参与者反馈了no或者协调者在等待响应时出现超时,都会导致事务中断,协调者向参与者发送rollback请求。
现实生活中也有类似的例子:
|
|
可能存在的问题:
- 参与者挂掉,如果在第一阶段发生,协调者直接给其他参与者发送rollback事务,在第二阶段发生,就必须等参与者恢复重新从协调者那边拿到状态做相应的操作(如果这里的事务只是单纯的replication,那我们只需将故障的参与者移除协调者的活跃列表可以正常进行,但是如果分布式事务本身必须要故障的参与者参与,那么整个系统必须阻塞直到参与者恢复)。
- 协调者挂掉,第一阶段挂掉,部分参与者prepared,部分参与者初始状态,备用协调者启动收集到参与者的状态后,可以继续发送prepared或者rollback。第二阶段挂掉,备用协调者启动后发现部分参与者是prepared,部分参与者是committed,继续发送commit。
- 协调者发送第一个commit的时候和接收的参与者同时挂掉,剩下的参与者全部是prepared状态,备用协调者启动以后不知道挂掉的参与者是什么状态,如果发送rollback可能参与者已经commit,commit可能不可逆,如果发送commit可能参与者已经被rollback,事务保存的数据已经丢失。无论新的协调者选择commit还是abort,最终参与者恢复时有可能是abort或者commit,这样会导致不一致,这也是导致2PC缺陷的根本原因:此时备用协调者无法知道之前的协调者作的决策,所以整个事务就处于阻塞的状态,只能等挂掉的参与者恢复才能继续。
3PC
Three-Phase Commit,三阶段提交,分为CanCommit、PreCommit、do Commit三个阶段。
三阶段提交是为了解决两阶段提交中出现的协调者和参与者共同挂掉导致的数据不一致的状况。
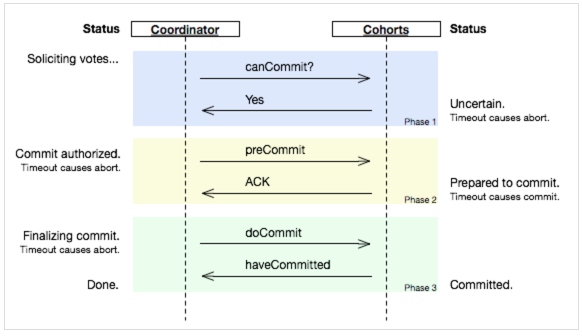
3PC最关键要解决的就是协调者和参与者同时挂掉的问题,所以加入了一个precommit状态标识。 为便于理解暂且把3pc的几个状态和2pc的对应成一样的:init,prepared,precommit,commit。 3pc在第一阶段协调者和参与者如果同时挂掉和2pc第一阶段一样,备用协调者看到的是prepared和init的状态或者全部是init或者全部是prepared状态,这个时候可以全部rollback。 协调者如果在precommit的时候和第一个参与者同时挂掉,备用协调者看到的全是prepared的状态,可以选择rollback,挂掉的第一个参与者恢复以后如果是rollback自然ok,如果是precommit,也可以rollback,这是和2pc最大的不同。 如果备用协调者看到了precommit的状态意味着之前的协调者做出的决策是precommit,可以把commit流程继续下去。 3pc的另一个关键是有timeout时间,所以无论是协调者或者参与者只要是活着的都知道怎么走下去。比如在发送precommit的过程中如果部分机器挂掉,部分机器是precommit的状态,部分机器是prepared的状态,协调者接收不到有些机器的响应就会发送rollback,那些precommit的机器就应该超大概率响应rollback,那些prepared的机器会超时rollback,最总达成状态一致。最后一个阶段即使部分机器接受不到commit命令最后也会在timeout以后commit达成一致。
可能存在的问题: 在doCommit阶段,如果参与者无法及时接收到来自协调者的doCommit或者rebort请求时,会在等待超时之后,会继续进行事务的提交。 所以,由于网络原因,协调者发送的abort响应没有及时被参与者接收到,那么参与者在等待超时之后执行了commit操作。这样就和其他接到abort命令并执行回滚的参与者之间存在数据不一致的情况。
Paxos
|
|
- Why paxos?我们已经有了2PC,3PC,为什么还需要paxos
- paxos可以保证有半数以上机器存活的情况下达到一致,增强了分布式系统的可用性,显然3PC不支持任何一台机器挂掉的情况
- Paxos是为了解决什么问题
- Paxos协议用于确定分布式系统中一个不可变变量的取值,这个取值是不可变,可被读取的。
- Paxos为什么可以应用在分布式存储系统中?
- 数据是可变的,以多个副本的形式存储,多个副本的更新序列是相同的,不变的。
- Paxos为什么基于消息传递而不基于共享内存?
- Paxos的原则是容错性一定要很强。如果这块共享内存出现问题,所有的副本都无法工作。
一个典型的场景是,在一个分布式数据库系统中,如果各节点的初始状态一致,每个节点都执行相同的操作序列,那么他们最后能得到一个一致的状态。为保证每个节点执行相同的命令序列,需要在每一条指令上执行一个“一致性算法”以保证每个节点看到的指令一致。
设计一个系统,来存储名称为var的变量。
- 系统内部由多个Accepter组成,负责管理和存储var变量。
- 系统对外提供api,用来设置var变量的值 : propose(var,V) => <ok,f> or
- 将var的值设置为V,系统会返回ok和系统中已经确定的取值f,或者返回error。
- 外部有多个Proposer机器任意请求系统,调用系统API(propose(var,V) => <ok,f> or
)来设置var变量的值。 如果系统成功的将var设置成了V,那么返回的f应该就是V的值。否则,系统返回的f就是其他的Proposer设置的值。
要设计以上系统存在以下难点:
- 管理多个proposer并发执行
- 容忍var变量的不可变性
- 容忍任意Proposer的故障
- 容忍半数以下的acceptor的故障
设计一:单个Accepter的情况
先考虑整个系统由单个acceptor组成。通过互斥锁的方式来管理并发的proposer的请求:
acceptor会保存变量var的值和一个互斥锁Lock:
- 接口prepare():加互斥锁,给予var的互斥访问权,并返回当前var的取值
- 接口release():用于释放互斥访问权
- 接口accept(var, v):如果已经加锁,并且当前var没有值,则将var的值设置成v,并释放锁。
proposer采用两阶段来实现: Step1、通过调用prepare接口来获取互斥性访问权和当前var的取值 如果无法获取到互斥性访问权,则返回,并不能进入到下一个阶段,因为其他proposer获取到了互斥性访问权。 Step2、根据当前var的取值f选择执行 1、如果f的取值为null,说明没有被设置过值,则调用接口accept(var ,v)来将var的取值设置成v,并释放掉互斥性访问权。 2、如果f的取值不为null,说明var已经被其他proposer设置过值,则调用release接口释放掉互斥性访问权。
这种设计存在的问题是:
- 如果单个acceptor挂掉,整个系统就挂了,
- 如果某个proposer在获取到互斥性访问权之后挂掉,acceptor再也无法接受其他proposer的访问请求,陷入死锁。
设计二:单个Accepter引入抢占式访问权
通过引入抢占式访问权来取代互斥访问权。acceptor有权让任意proposer的访问权失效,然后将访问权发放给其他的proposer。
在方案二中,proposer向acceptor发出的每次请求都要带一个编号(epoch),且编号间要存在全序关系。一旦acceptor接收到proposer的请求中包含一个更大的epoch的时候,马上让旧的epoch失效,不再接受他们提交的取值。然后给新的epoch发放访问权,让他可以设置var变量的值。
为了保证var变量取值的不变性,不同epoch的proposer之前遵守后者认同前者的原则:
- 在确保旧的epoch已经失效后,并且旧的epoch没有设置var变量的值,新的epoch会提交自己的值。
- 当旧的epoch已经设置过var变量的取值,那么新的epoch应该认同旧的epoch设置过的值,并不再提交新的值。
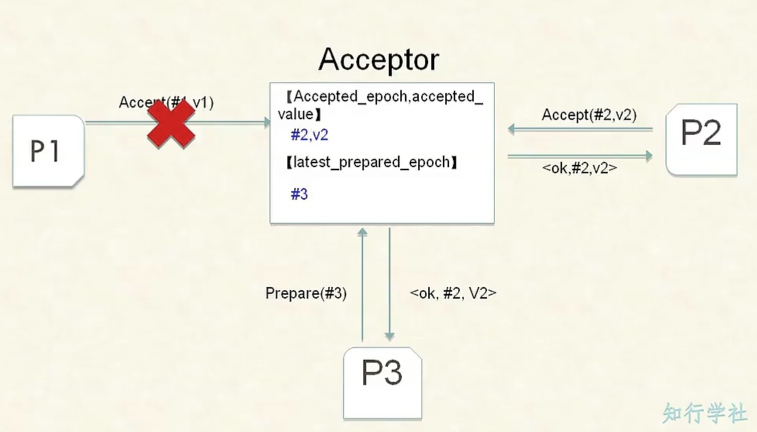
现在解决了死锁的问题和var取值不可变的问题,还需要引入多个Acceptor。
设计三:Basic Paxos
在设计二的基础上添加多个acceptor,并采用少数服从多数的原则。 第一阶段:
- Proposer选择一个全局唯一的提案编号epoch,然后向acceptor的某个超过半数的子集发送编号为epoch的prepare请求。
- acceptor会记录自己已经批准过的最大epoch值,如果一个acceptor收到一个编号为epoch的prepare请求,且epoch编号大于该值,它会将已经批准过的最大epoch值对应的提案作为响应返回,并承诺不在接收比当前epoch值更小的epoch请求。
第二阶段:
- 如果Proposer获取到的值都为空,则说明旧的epoch无法形成确定性取值,这时候努力使自己的当前值成为最终的确定性取值:向epoch对应的所有acceptor提交取值,如果得到半数以上 acceptor的成功返回,则返回ok,否则返回error(被新的epoch抢占或者acceptor故障);
- 如果Proposer获取到的值存在,而且这个存在值出现了半数以上,则说明已经出线了确定性取值,直接认同当前的确定性取值 ,返回ok;
- 如果Proposer获取到的值存在,但是没有任何一个值存在半数以上,这时认同返回值中最大epoch对应的取值f,并努力帮它称为最终的确定性取值:向epoch对应的所有acceptor提交<epoch,f>。
具体由以下几种情况:
已经形成确定性取值的情况:
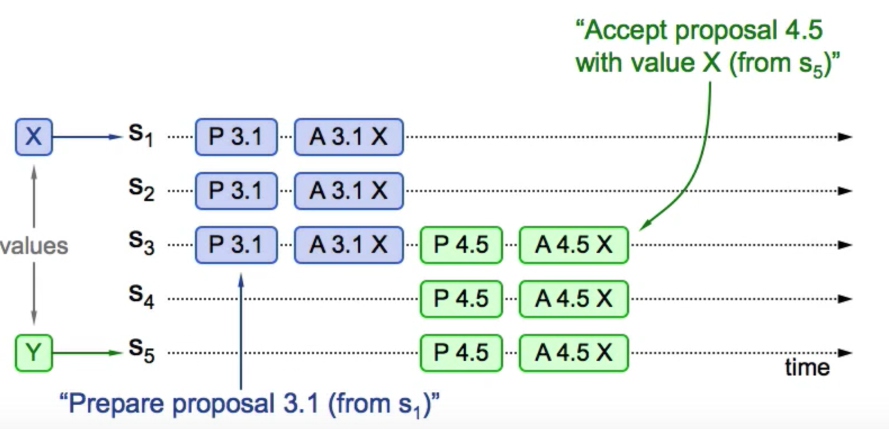 可以看到图中由Server 1 发起的epoch为3请求经过prepare(P 3.1)和accept(A 3.1 X)已经形成了确定性取值X,Server 5 发起的prepare请求通过Server 3看到了先前形成的取值X并予以认可,通过给Server3,Server4,Server5发送accept(A 4.5 X)成功使得X成为一致性取值。
可以看到图中由Server 1 发起的epoch为3请求经过prepare(P 3.1)和accept(A 3.1 X)已经形成了确定性取值X,Server 5 发起的prepare请求通过Server 3看到了先前形成的取值X并予以认可,通过给Server3,Server4,Server5发送accept(A 4.5 X)成功使得X成为一致性取值。
还未形成确定性取值,但是后来的prepare请求获取到了已有的值:
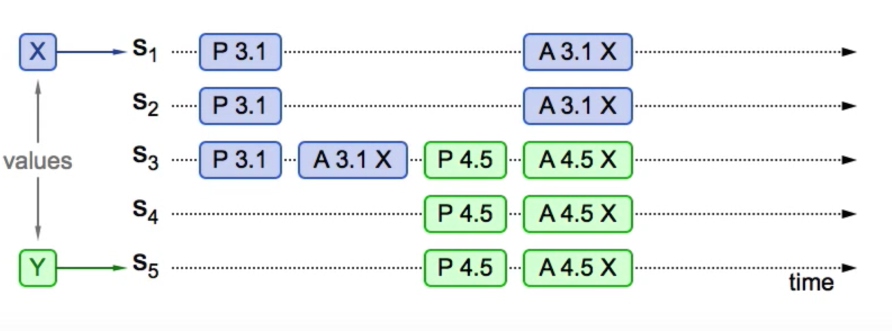 可以看到图中由Server 1 发起的epoch为3请求还未形成确定取值,但是Server 5 发起的prepare请求通过Server 3看到了先前形成的取值X,同样予以认可,通过给Server3,Server4,Server5发送accept(A 4.5 X)成功使得X成为一致性取值。
可以看到图中由Server 1 发起的epoch为3请求还未形成确定取值,但是Server 5 发起的prepare请求通过Server 3看到了先前形成的取值X,同样予以认可,通过给Server3,Server4,Server5发送accept(A 4.5 X)成功使得X成为一致性取值。
还未形成确定性取值,后来的prepare请求未能获取到任何已有的值:
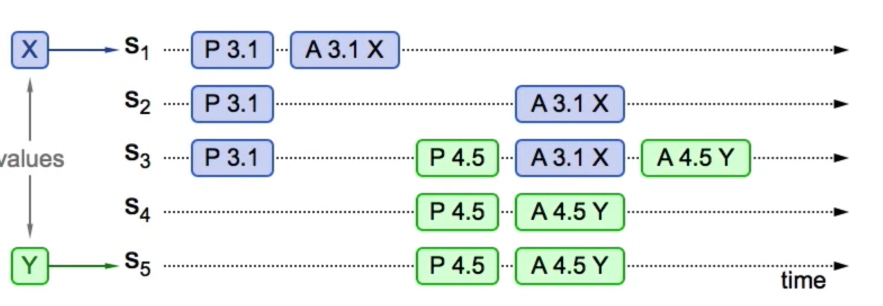 可以看到图中由Server 1 发起的epoch为3请求还未形成确定取值,而且Server 5 发起的prepare请求未获得任何已有的值,所以Server 5 提交了自己的取值Y,由于Server 3被更新的epoch值
可以看到图中由Server 1 发起的epoch为3请求还未形成确定取值,而且Server 5 发起的prepare请求未获得任何已有的值,所以Server 5 提交了自己的取值Y,由于Server 3被更新的epoch值4抢夺了访问权,所以不会接受Server 1 发来的对应epoch值3的accept请求,而会接受epoch值4对应的accept请求,将值设置为4,至此Y就获得了超过半数的server认可,在下一轮中就可以成为全体的一致性取值。
这样的设计巧妙的利用了超过半数。
如果一个值已经成为了确定性取值,意味着他已经获得了超过半数的server的认同,同样意味着如果给超过半数的子集发送prepare请求时,肯定可以看到其中之一server是包含了这个确定性取值的。通过这个prepare操作,不仅避免了死锁问题,而且让server有机会看到先前的取值。
可以说,paxos给我们提供了完美的解决分布式系统的一致性问题的方案。
参考链接: http://www.tudou.com/programs/view/e8zM8dAL6hM/ http://jianbeike.blogspot.com/2016/04/2pc3pc.html
文章作者 run
上次更新 2016-07-28