在JAVA中执行shell
文章目录
今天抽时间解决了一个升级Elasticsearch后带来的一个问题。
起源是最初开发的一个用于维护搜索的项目infiniti,主要功能是重建索引,创建备份,维护分词,排序控制等。其中重建索引的部分,原先是基于elasticsearch-jdbc来做的,为了方便起见,从数据库导入数据的部分需要执行shell脚本。在前面一篇文章中也有说到,ES升级到5.0之后,数据库同步的部分也切换到了logstash,同样是通过执行shell脚本的方式同步数据。
原先执行shell脚本的姿势是:
|
|
一直稳定运行了大半年。
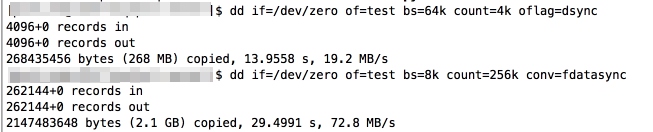
但是更换到logstash的shell脚本之后,线上环境在执行shell的时候都会抛出OOM异常:
|
|
因为daily环境没有出现过问题,上线当晚顿时吓出一身冷汗,因为ES的相关的搜索代码已经更新了,配套的logstash也是箭在弦上不得不发,第一件事(勿喷):加jvm内存 -> 增加机器内存。
通过free命令和top命令可以看到机器的可用内存还非常非常多:
|
|
而logstash的jvm参数配置是:
|
|
初始和最大堆内存都是2G,显然可用内存是远远多余2G的。
再观察OOM留下的dump文件:
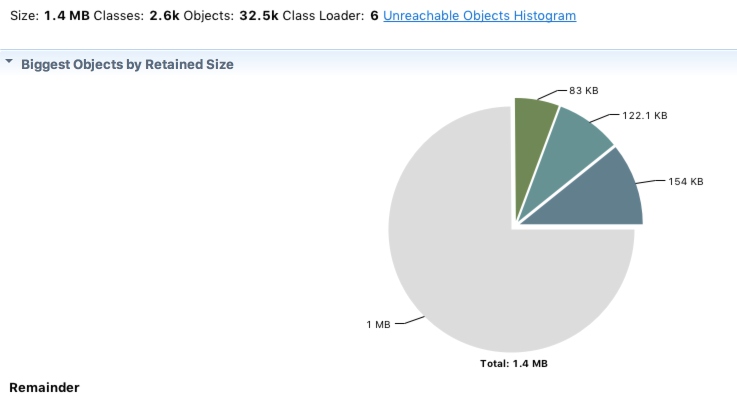 整个dump文件只有1.4M,怎么可能耗尽内存?
整个dump文件只有1.4M,怎么可能耗尽内存?
百思不得其解,观察了一下线上机器和daily机器的区别:daily机器的内存(4G)只有线上机器增加内存前(8G)一半的内存,但是存在swap交换区。
因为线上使用的阿里云ECS默认是不配置swap的,原因是OOS的读写性能比较差:
而daily机器是SSD,所以读写性能较优,存在swap分区:
|
|
是不是因为daily的swap分区为执行shell瞬间膨胀的内存用量提供了缓冲所以使得daily机器未出现问题? 因而尝试了给阿里云ECS配置了swap分区,参考云服务器 ECS Linux SWAP 配置概要说明。 然而,依然没有起任何作用。
仔细想了想,在JAVA中执行Shell脚本,除了Runtime.getRuntime().exec(),还有ProcessBuilder.start(),遂改写代码为ProcessBuilder实现。
然而,依然没有起任何作用。研究了一下,发现Runtime.getRuntime().exec()底层其实就是使用ProcessBuilder.start(),这两个是一家,都依赖于:
|
|
后来搜到了stackoverflow上的一个问答How to solve “java.io.IOException: error=12, Cannot allocate memory” calling Runtime#exec()?,跟我遇到的问题一模一样。
原来UNIXProcess.forkAndExec()在新建进程的时候,会将现有进程占用的内存大小完全fork一份出来,不管新进程使用的内存或大或小。
fork() call actually duplicates the entire memory of the currently running process. If you have a java program with 1.2 GB memory and 2GB total,it will fail。 fork()的调用实际上复制了当前进程的整个内存。如果你当前程序声明了1.2G内存,而内存共有2G,这个命令就会失败(因为剩余的0.8G不足存放复制出来的1.2G)
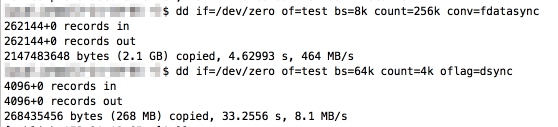
这是一个多么操蛋的设定。。 好吧,定位了问题,下面我们想办法解决。 首先,尝试命令:
|
|
这个命令的含义是:
overcommit_memory set to 1 every malloc() will succeed. Linux will start randomly killing processes when you’re running out of memory 将overcommit_memory设置为1,每次通过malloc()命令来划用内存都会返回成功,如果可用内存不足,系统会开始随机停止一些耗大量内存砸进程(OOM KILL)
然而,依然没有起任何作用。
再认真想了一想,原来增加jvm的直觉恰恰是与真相背道而驰了。我一再增加现有进程的内存,就会导致fork的时候,需要的内存越多,就越要出现OOM!所以正确的姿势是,减少现有进程声明的内存:
|
|
终于,整个世界清静了。
PS.阿里云,能退我的内存钱吗。。 PPS.再也不在紧急关头先加配置了。。
文章作者 run
上次更新 2017-01-08