MySQL到Elasticsearch的同步之路
文章目录
六个月前写买好车搜索的Elasticsearch实践:初体验这篇文章的时候,我司刚刚迁移到Elasticserach,六个月之后的今天跟我最开始什么都不懂的时候搭起来的架构还是一模一样,这几天稍微有点时间,将Elasticsearch升级到了5.0.2,顺便整理了一下架构。 这一篇主要记录搜索与数据库同步的一些变化。
洪荒时代
Elasticsearch 2.0 之前,同步数据到Elasticsearch的功能由一个官方提供的插件(plugin)占领:river。通过实现不同的river插件,可以将数据从数据库,消息队列,nosql等等同步到Elasticsearch中,比如:elasticsearch-river-rabbitmq、elasticsearch-river-couchdb等等。
以plugin方式运行的形式如图:
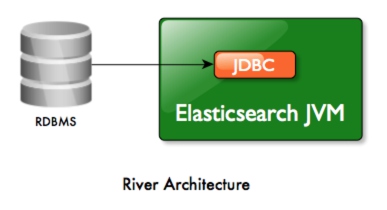 可以看到,插件与Elasticsearch运行在同一个jvm上,显然这会导致一系列的问题,正如Deprecating Rivers中所说:
可以看到,插件与Elasticsearch运行在同一个jvm上,显然这会导致一系列的问题,正如Deprecating Rivers中所说:
What was the problem we were witnessing? Cluster stability. You see, by their nature, rivers deal with external systems, and those external systems require external libraries to work with. Those are great to use, but they come with an overhead. Part of it is built in overhead, things like additional memory usage, more sockets, file descriptors and so on. Others, sadly, are bugs.
插件的运行机制将外部数据和其他运行库的不稳定性引入了Elasticsearch,所以Elasticsearch官方从 Elasticsearch 2.0 开始去除了这一方式的支持,转而推荐getting data to Elasticsearch from "outside" the cluster即从集群外部将数据导入Elasticsearch的方式。
Elasticsearch-JDBC
elasticsearch-jdbc无疑是Elasticsearch 5.0 之前最炙手可热的数据库同步方案,他的优势是开源,用java语言编写,配置化。这也是我司最早时候采用的方案。 Elasticsearch-JDBC不可否认也存在一些不足,主要有:
不支持多数据源
需要对源代码做一些hack
SQL以json形式保存,因此不能带有特殊字符
比如有一句SQL:select replace(columnA, '.' ,'' ) from dual,需要改造成基于ASCII编码的格式:select replace(columnA, 0x2E, '') from dual
内存泄露问题
Elasticsearch-JDBC在使用过程中会出现OOM的问题,特别是在interval设得很短的时候,解决的方式可以参考这个issue。
数据缺失问题
脚本读取的是从库,主从同步需要一定时间,如果数据写入了,但是未及时同步到从库,就会导致中间一些数据丢失,可以用一个简单粗暴的方式解决,就是每次运行读取(上次执行时间 - 30S )这个时间点之后更新的数据,这里不用考虑重复的问题,因为同样的ID在Elasticsearch中会自动转为update:
|
|
最终线上的增量同步脚本如下:
|
|
虽然很简陋,但是也矜矜业业运行了半年时间没出过问题,可以作为迅速上线的一个方式。
同样的,作为开源软件的劣势就是很难及时跟上Elasticsearch的更新步伐,Elasticsearch-JDBC暂时还不支持Elasticsearch 5.0,具体可以跟踪这个issue。
Logstash
为什么不用Logstash?
正如Elasticsearch-JDBC的作者@jprante 所说:
I have only a rough idea about Logstash JDBC and how it works, it seems to use the JRuby features for JDBC. Not sure how Ruby interferes in such a process when SQL database types are mapped by JDBC types, then mapped to Java, then to Ruby, then to JSON, then indexed in ES and then back to an application, but there might be shortcomings. SQL to JDBC to Java is already a challenge on its own.
Logstash基于Ruby语言,Logstash JDBC采用JDBC的java驱动,意味着,数据从数据库到Elasticsearch经历了JDBC -> JAVA -> Ruby -> JSON -> ES,越多的步骤意味着越多出错的概率,为何不采用更为稳定和直接的JDBC -> JAVA -> ES呢?这也是Elasticsearch-JDBC将会继续维护的原因。
为什么要用Logstash呢?
支持Elasticsearch 5.0, 而且有官方支持
便于日后扩展输入和输出
Logstash提供了很多很多的输入输出插件的支持
Logstash JDBC更快
根据我在测试环境的观察,11W条记录相同类型的索引,Elasticsearch-JDBC完成索引耗时90S,Logstash-JDBC只需要50S。
占用系统资源更少
根据我在测试环境的观察:
Elasticsearch-JDBC的系统资源使用:
 Logstash-JDBC的系统资源使用:
Logstash-JDBC的系统资源使用:

迁移到Logstash
具体可以参考官方的文档:jdbc 和官方的使用案例:INSERT INTO LOGSTASH SELECT DATA FROM DATABASE
主要有下面几个技巧
SQL剥离
当然可以将SQL直接写入配置文件的statement配置项,但是会遇到与Elasticsearch-JDBC中同样遇到的特殊字符的问题和文本编码的问题。
更好的方式是将查询脚本存放在一个单独的SQL文件中,通过指定statement_filepath配置项来定位。
时区指定
如果不定义jdbc_default_timezone配置项,你的执行时间可能会受到系统环境的影响。这个配置项需要输入UTC中定义的时区,详见:wikipedia
保存上一次执行的进度
如果你的增量依赖于数据库的某个字段(比如自增的ID),可以配置:
|
|
Lostash会将上一次导入数据的最大id存放在.logstash_jdbc_last_run文件中。
如果增量脚本是基于时间戳,则无需配置use_column_value。
使用的方式都是一样的,在SQL中使用:sql_last_value来引用先前的执行结果。
最终线上的增量同步脚本如下:
|
|
其他
当然,从数据库同步到Elasticsearch还有很多更好的方式,比如
- 解析数据库的binlog
- 直接通过hadoop构造lusence索引推送到Elasticsearch 等等,可以参见Elasticsearch中文社区20160618杭州线下聚会纪要
这些方式可以解决数据库物理删除同步到Elasticsearch的痛点。 但是更好的方式意味着更高的开发成本,希望日后可以有时间实现。
binlog这里不得不吐槽一下阿里云的RDS,如果自定开通binlog订阅则无法使用阿里云的DTS,如果要使用DTS必须使用阿里云提供的付费binlog订阅服务。 不得不感慨,这是一个最好的时代,也是一个最坏的时代。
文章作者 run
上次更新 2016-12-11